
MongoDB〜OSSのNoSQLサーバ〜
MongoDBとは、ビッグデータやIoTのデータ処理に利用されるオープンソースソフトウェアのNoSQLサーバです。MongoDB Enterprise Advancedという商用版もあります。2019年にはAWSがMongoDB互換のAmazon Document DBの提供を開始するなど、NoSQLとしては最もスタンダードなソフトウェアです。Linuxだけでなく、Windows、MacOS、Soalrisなどでも利用することができます。
MongoDBとは
MongoDBとは、ドキュメント指向のデータベースを採用したNoSQLサーバです。2007年にDoubleClickのチームが開発し、オープンソースソフトウェアとして公開しています。商用版はMongoDB Enterprise Advancedです。
MongoDBは、多くのNoSQLが採用しているKVS(Key Value Store)ではなく、ドキュメント指向データベースを採用しており、RDB(Relational Database)に近い検索性を備えています。さらに、MongoDBはインメモリで動作するため、高速なデータ処理を行うことができます。また、データの分散配置を行うことも可能となっており、スケーラビリティ・アベイラビリティの高いデータベースを構築することができます。MongoDBのレプリケーション機能では、プライマリノードが故障した場合には、自動的にスレーブノードが昇格するなど、冗長性にも優れています。
このようにMongoDBは、NoSQLとしての高速性だけでなく、システムの拡張性・冗長性にも優れています。また、コンテナでも管理しやすい通信方式を採用していることなどから、ビッグデータやIoTのデータ処理などでもよく利用されています。
MongoDBの特徴
MongoDBの主な特徴は、次のとおりです。
高速で導入しやすいNoSQLデータベース
MongoDBは、高速なデータ処理ができ、なおかつKVSよりも高機能でRDBと同じような感覚で扱うことができます。そのため、近年、従来のDBの開発者を中心に、非常に人気があるNoSQLのデータベースです。NoSQLではありますが、検索したデータのソートなど、データベース側で行える処理もそろっていて、比較的対比がとりやすい構造になっています。そのため、RDBに慣れたプログラマでも、アプリケーションの開発が行いやすくなっています。また、MongoDBでは、RDBMSのようにデータの形式を決めておく必要がないため、容易に導入することができます。MongoDBは、JSONに似た形式でデータを保存しており、Web APIを使ってアクセスします。検索結果もJSONに似た形式で出力されます。このため、外部システムとも容易に連携することができます。
ただし、RDBMS(Relational DataBase Management System)で利用できるトランザクションやデータ結合を行うことはできません。
冗長化可能で安全に利用できる
MongoDBでは、冗長化をサポートしているため、重要な処理でも利用することができます。MongoDBでは、レプリカセットと呼ばれる冗長構成を組むことで冗長性を担保します。レプリカセットを組んだ場合、データはメインとなるプライマリサーバに保存され、セカンダリサーバにもコピーされます。レプリカセットを作成すれば、1台のサーバが障害で停止してもデータを失うことがなくサービスを継続することができます。
レプリカセットとプライマリ、セカンダリ
レプリカセットは、MongoDBのデータの複製機能です。レプリカセットでは、データの書き込みは1台で行います。このデータの書込みを行うノードをプライマリと呼びます。また、それ以外の複製ノードをセカンダリと呼びます。データの検索や読み込みはセカンダリからも行うことができるため、書き込みよりも読み込みが少ないシステムではレプリカセットだけで負荷を分散することができます。
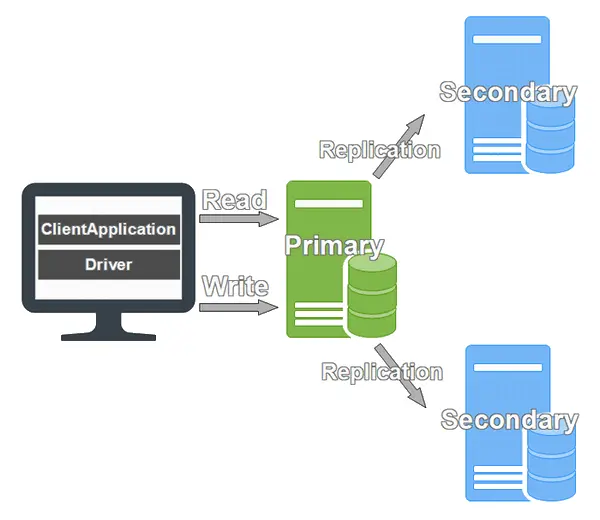
自動フェールオーバー
MongoDBでは、プライマリが停止すると、セカンダリがプライマリに自動昇格します。どのセカンダリを昇格するかは、システム内の全ノードによる投票で決められます。サーバ数が偶数だと投票では決まらない可能性があるため、レプリカセットを構成するには、最低でも3台のMongoDBノードが必要です。
アービター
アービターは、データを持たないMongoDBの特別なノードです。自動フェールオーバーの時に、プライマリを選ぶ投票に参加することができます。データの読み込みにも書き込みにも関与しないため、ほとんど負荷がかかりません。
ヒドン(Hidden)とデータのバックアップ
ヒドンは、特別なセカンダリです。セカンダリではありますが、プライマリに昇格することがないノードです。
MongoDBでデータベースのバックアップをとるためには、データベースの更新を一時的に停止する必要があります。そのため、特別なセカンダリを作って、一時的にデータベースの更新を停止してバックアップを取るという手法が使われます。データベースの更新を中止している時に、プライマリに昇格することはできないため、このような用途で利用するセカンダリはヒドンに設定しておきます。
負荷分散が可能で柔軟にスケールアップできる
PostgreSQLやMySQLでは、導入後に負荷が増加すると、システムのスケールアップが問題になることが多くあります。MongoDBでは、データを複数のサーバに分散して保存する機能を備えていて、このような問題に対処することができます。この機能をシャーディングと呼びます。MongoDBの導入後に負荷が増加してサーバのパフォーマンスが低下した場合でも、シャーディングの機能を使ってサーバの台数を増やすことで、スケールアウトを行うことができます。
シャーディング
シャーディングとは、MongoDBの複数のノードでデータの分散を行うことを指します。シャーディングには、configサーバとmongosサーバ、シャーディングクラスタサーバが必要です。
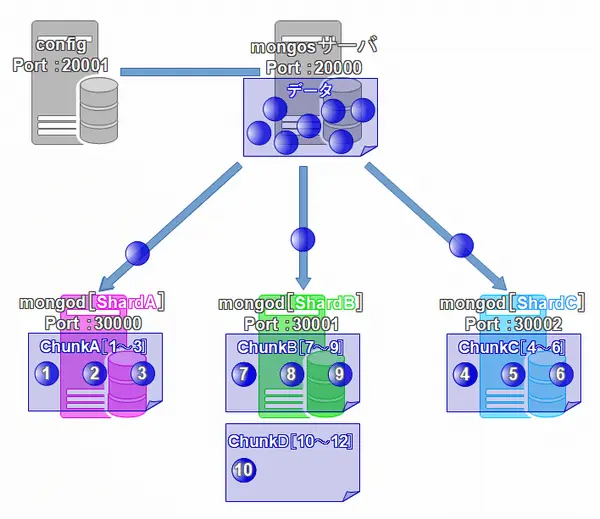
シャーディングクラスタサーバ
シャーディングクラスタサーバは、実際にデータを保存するサーバです。シャーディングクラスタサーバは可用性を高めるため、多くの場合、レプリカセットを利用し冗長化を行います。MongoDBのシャーディングでは、データは「チャンク」と呼ばれる単位で管理されます。コレクションのデータは、設定した最大サイズ(標準では64MB)になるとチャンクに分割されます。データが格納されるサーバは、シャードキーによって決定され、各ノードが持っているチャンク数が均等になるように自動的に配置されます。
mongosサーバ
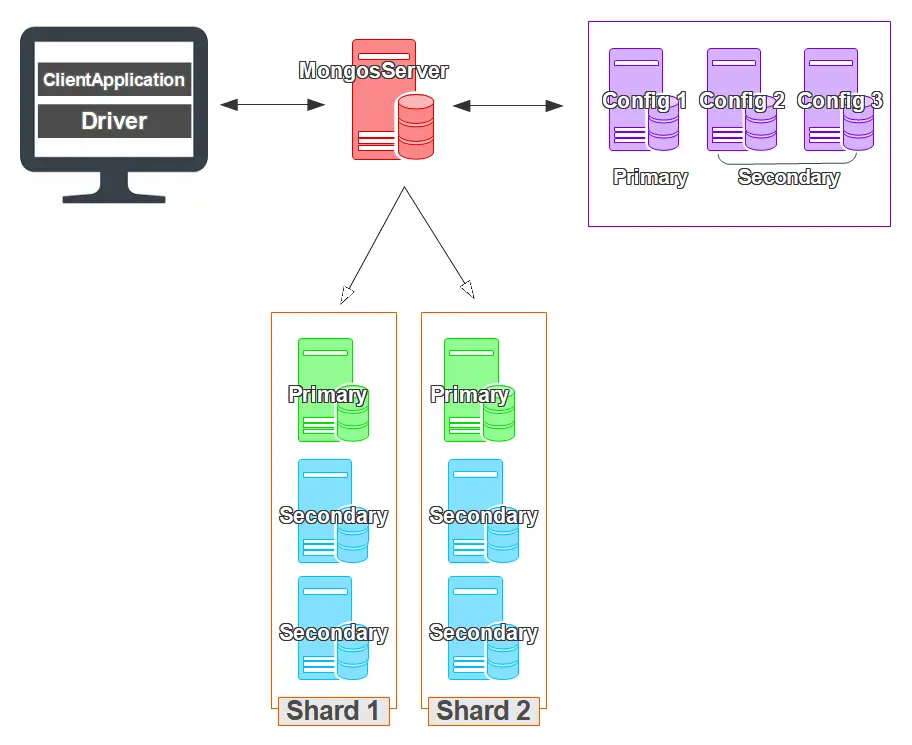
mongosサーバは、MongoDBでシャードを利用するときに処理を振り分ける役割を持っています。mongosサーバは、クライアントからの問い合わせを処理し、シャードクラスタ内の適切なデータを持ったノードに処理を振り分けます。そのため、シャーディングを利用するためには、必ずmongosサーバが必要です。ongosサーバは、特に状態を保持しないため、比較的容易に冗長構成を取ることができます。
configサーバ
configサーバは、MongoDBシステム全体の設定を管理するサーバです。シャードに関する情報もconfigサーバが管理しているため、configサーバが停止するとシャーディングに関する情報の更新ができなくなります。そのため、MongoDBでシャーディングを使った負荷分散を行う場合には、configサーバの冗長性も確保しておくことが重要です。MongoDBのconfigサーバも、レプリカセットを作成することで冗長化することができます。そのため、多くの場合シャーディングとレプリケーションセットはセットで利用します。
MongoDBのデータ構造
MongoDBは、NoSQL型のデータベースですが、RDBに似た構造でデータを管理することができます。ただし、いわゆるリレーショナルなデータ構造は取ることはできません。つまり、データの相関関係を表現することはできません。
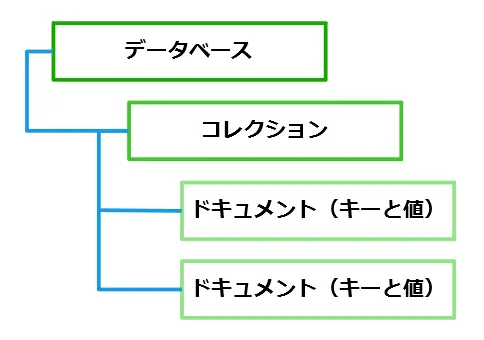
最も基本的な構造は、データベースです。MongoDBでは、データベースの中にコレクションを作成します。そして、コレクションには、キーの名前と値から構成されるドキュメントを配置することができます。RDBと比較すると、コレクションはテーブルに、ドキュメントがレコードに、フィールドが列に相当します。
つまり、次のような構造となっています。
MongoDBは、RDBと異なり厳密なスキーマを持ちません。例えば、データベースやコレクションは、特別に定義しなくても、利用しようとしたときに自動生成されます。また、RDBではテーブルのスキーマはCREATE TABLEで事前に定義し、レコードの種類を増やすにはALTER tableを使ってテーブルの定義を変更する必要があります。しかし、MongoDBではより柔軟で、このような定義をしておく必要はありません。
MongoDBの操作
MongoDBでは、データベースの操作はSQLとは異なっています。ただし、SQLと対応づけしやすいコマンド構造になっています。例えば、ドキュメントの挿入(SQLのINSERT)にあたるコマンドはinsertです。同様に、ドキュメントの更新(SQLのUPDATE)にあたるコマンドもupdateと分かりやすくなっています。また、ドキュメントの取得(SQLのSELECT)にあたるコマンドはfind、ドキュメントの削除(SQLのDELETE)にあたるコマンドはremoveです。update、find、removeの検索条件では、SQLで使う演算子(=<>など)の代わりに、$lt、$gtなどのクエリセレクタを使うことができます。また、findでは結果を取得するフィールドも指定することができます。
MongoDBの用途とシステム構成
このような特徴から、MongoDBは以下のようなシステムへの導入が適しています。
- 大量にあるデータを高速に処理したい
- アクセス数に合わせてデータベースを拡張していきたい
- データの冗長化を行いたい
大規模なデータベースでは、シャーディングもレプリカセットも有効にしたシステム構成となります。
MongoDBの商用版
商用サポートが必要な場合には、MongoDB Enterprise Advancedという商用版も用意されています。商用版には、OSS版にはない以下の機能があります。
統合管理インタフェースOps Manager
MongoDB Enterprise Advancedには、Ops Managerと呼ばれる統合管理インタフェースがあります。Ops Managerでは、WEBインタフェースで以下の操作が可能です。
- レプリケーションクラスタの構築
- シャーディングクラスタの構築
- データの追加/削除
- サーバ状況などのモニタリング
- データのバックアップ/リストア
このようにOpsManagerを利用することで、コマンドラインでの作業になれていない人でも、クラスタの構築や、データの確認等をWEBインタフェースから操作できます。
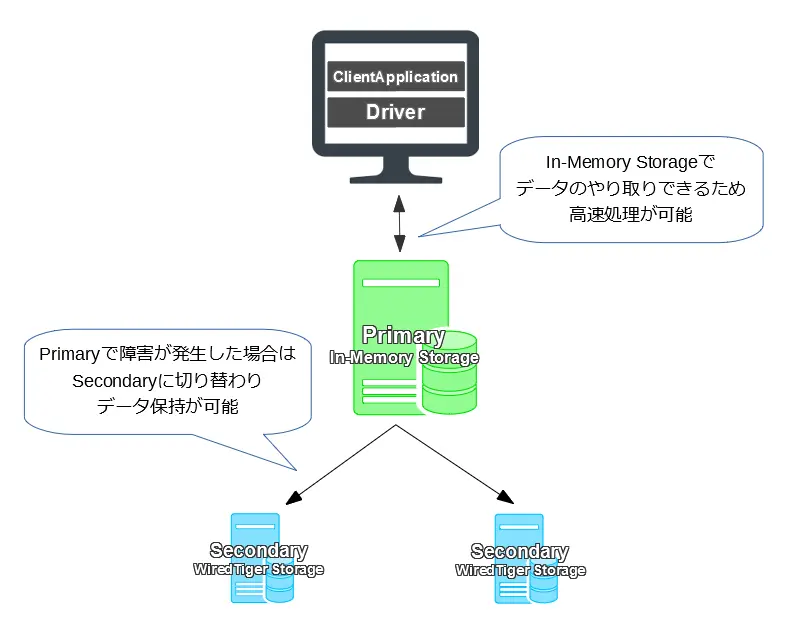
In-Memory Storage
MongoDB Enterprise Advancedでは、In-Memory Storageと呼ばれるストレージエンジンを利用することができます。OSS版のMongoDBで利用できるストレージエンジンは、データを永続的に保存するため、データが増えるに連れ、メモリ使用量も増加します。MongoDBはインメモリで動作するため、高速なデータ処理を行うことができますが、OSS版ではメモリ使用量がメモリを超えると処理速度は一気に落ちます。一方でIn-Memory Storageでは、データは非永続的で、保存を行いません。データをメモリ上に保存するため、特に書き込みに関する処理で高速処理が可能です。
商用版とOSS版の性能
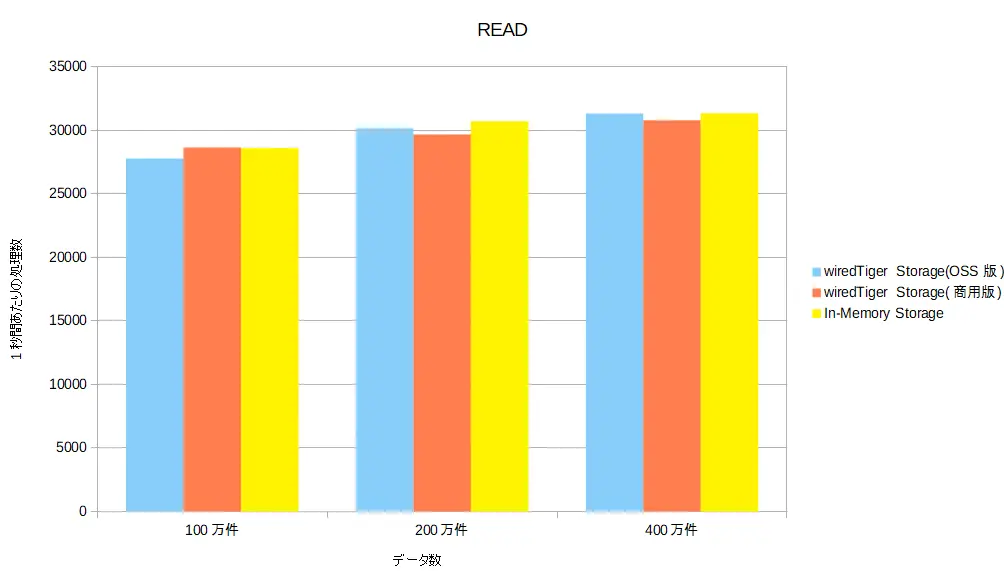
データ処理数グラフ(READ)
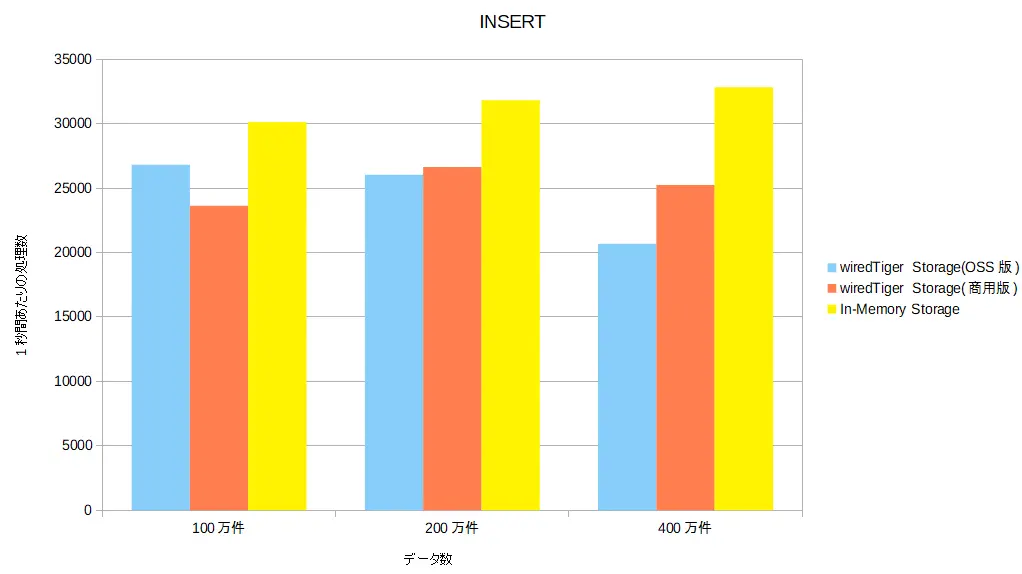
データ処理数グラフ(INSERT)
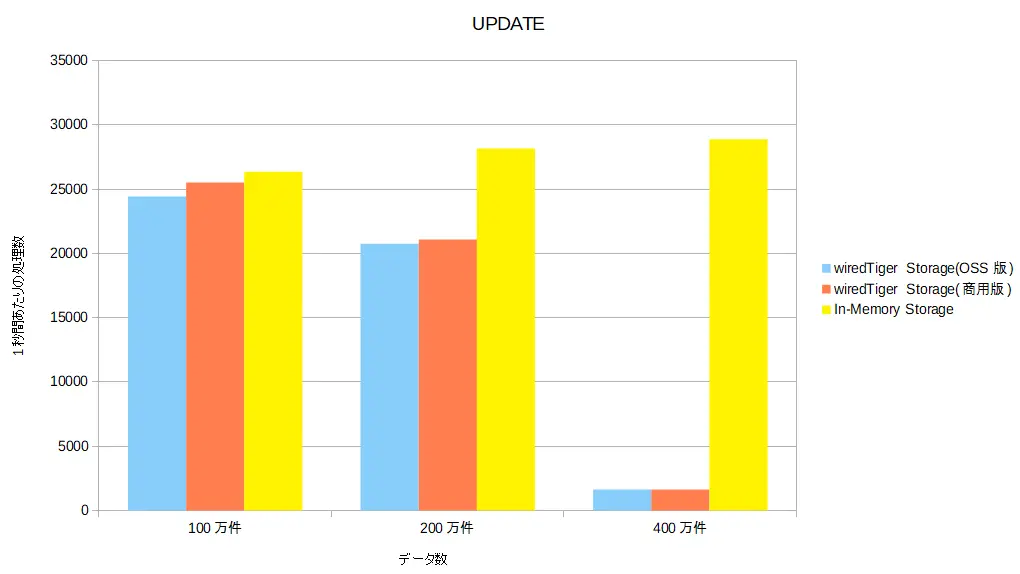
データ処理数グラフ(UPDATE)
ただし、In-Memory Storageはデータが非永続的のため再起動がかかるとデータが消えてしまいます。これを解決するためには、レプリカセットを行いデータをレプリケーションする必要があります。
デージーネットの取り組み
デージーネットでは、IoTやビックデータの解析システムなどを提案しています。最近では、バックエンドのデータベースとしてMySQLやPostgreSQLではなく、NoSQL型のデータベースを採用することも多くなっています。特に絶対に失ってはいけないデータを扱うとき、高速なデータベース検索が必要なときなどにMongoDBを推奨しています。デージーネットでは、システムの安全性を非常に重視し、シャーディングやレプリカセットを使って冗長性を考慮したシステムをご提案します。
デージーネットでは、システム構築サービスを提供したお客様には、導入後支援サービスとして、Open Smart Assistanceを提供しています。これは、ソフトウェア単体のサポートではなく、Linuxなどを含むシステム全体に対するサポートです。MongoDB単体のサポートはMongoDB Enterprise Advancedのサポートを推奨しています。
MongoDB「情報の一覧」
MongoDB Enterprise Advanced調査・検証報告書
MongoDBの商用版についての調査報告書です。オープンソース版との違いや商用版を使うことのメリットなどを詳しく報告しています。
IoTプラットフォームで使われるOSS「IoTデータ収集プラットフォーム」
IoTデータ収集プラットフォームは、IoTエンドポイントから収集したデータを保管するための設備です。データ量が、それほど多くない場合には汎用的なストレージ、オブジェクトストレージをそのまま利用することができます。データ量が多い場合には、NoSQL、負荷分散型のデータベース、高速な全文検索エンジンなどが使われます。
デモのお申込み
もっと使い方が知りたい方へ
操作方法や操作性をデモにてご確認いただけます。使い方のイメージを把握したい、使えるか判断したい場合にご活用下さい。デモをご希望の方は、下記よりお申込みいただけます。
