
- Graylog
〜ログ管理の課題を解決するOSS〜 - ここでは、OSSの統合ログ管理・監視ソフトGraylogの特徴と、Graylogに対するデージーネットの取り組みについてご紹介します。
- ログ管理サーバとしてのGraylog
- ここでは、Graylogのログ管理に焦点を当て、その特徴を紹介します。
- ログ管理のGUI
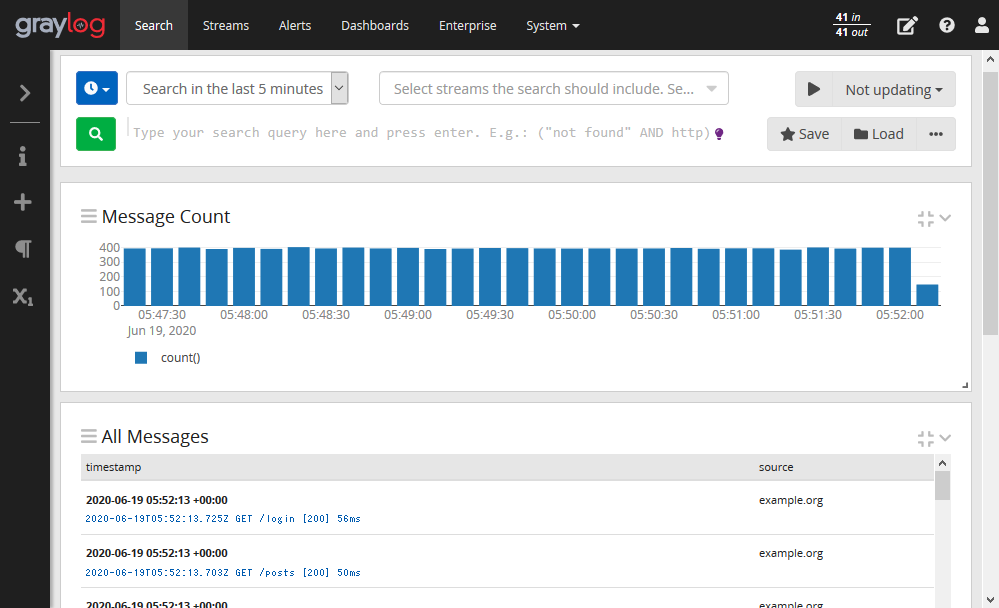
- Graylogでは、ログサーバのシステム管理をGUIから行うことができます。ここでは、Graylogの特徴の一つであるGUIインタフェースについて解説します。
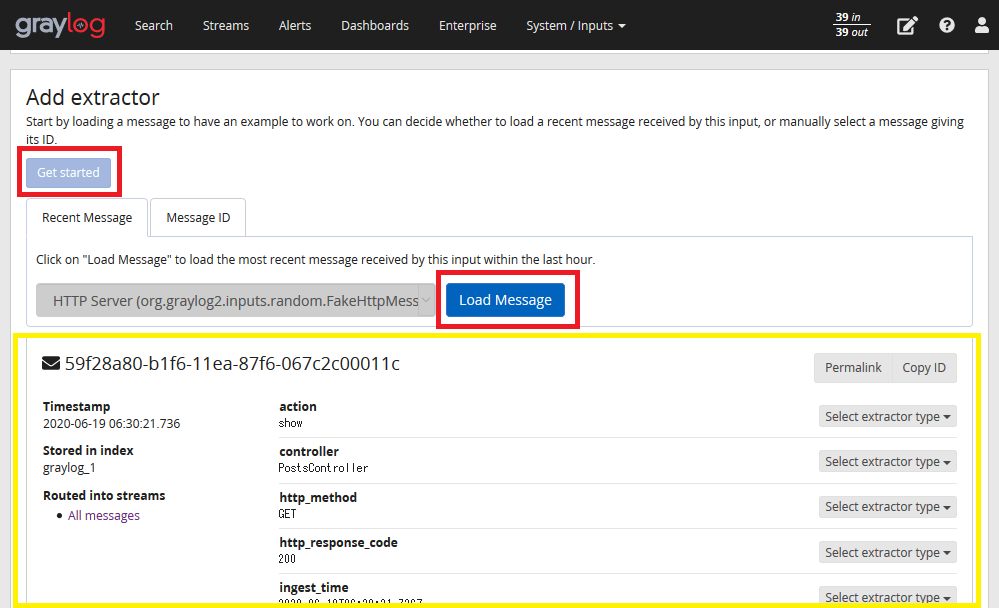
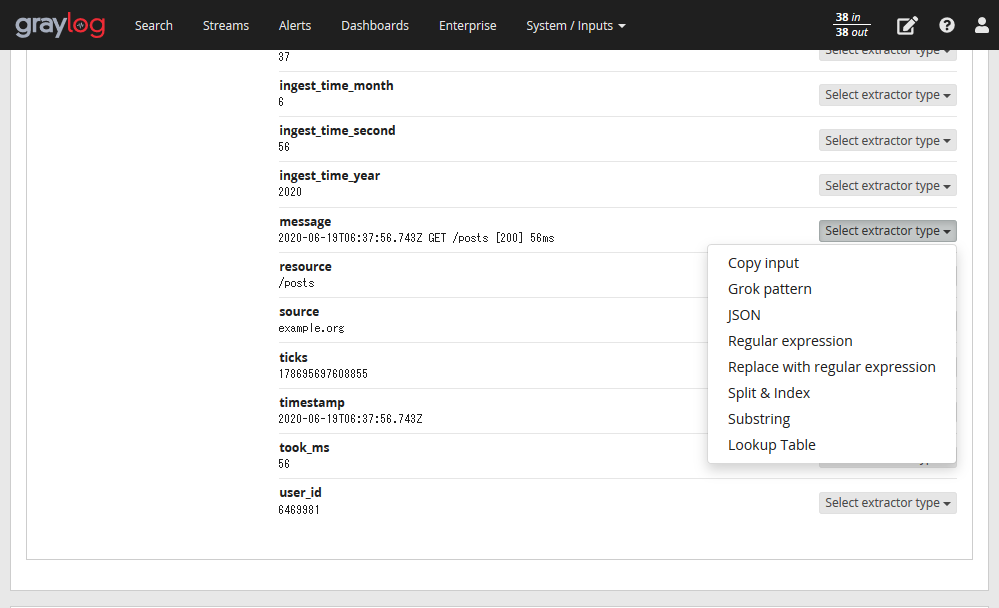
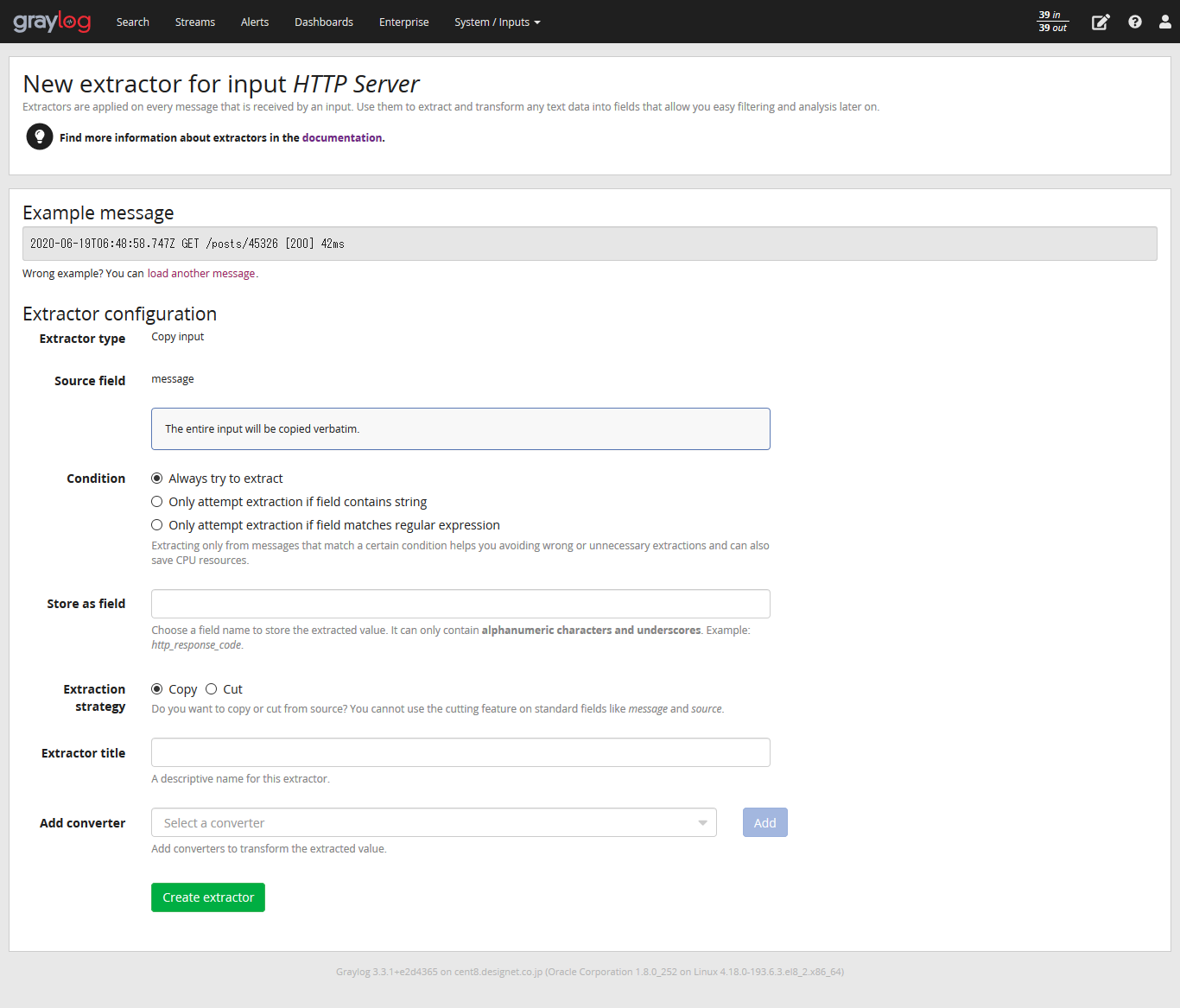
- ログ解析とログ収集
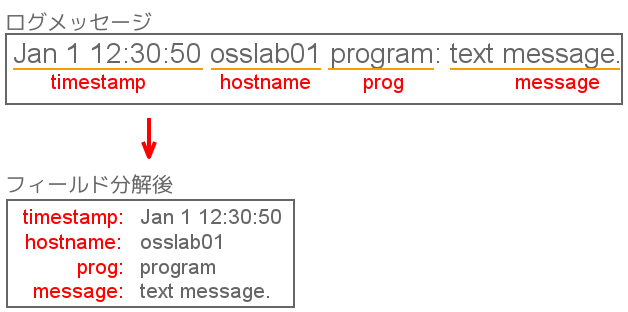
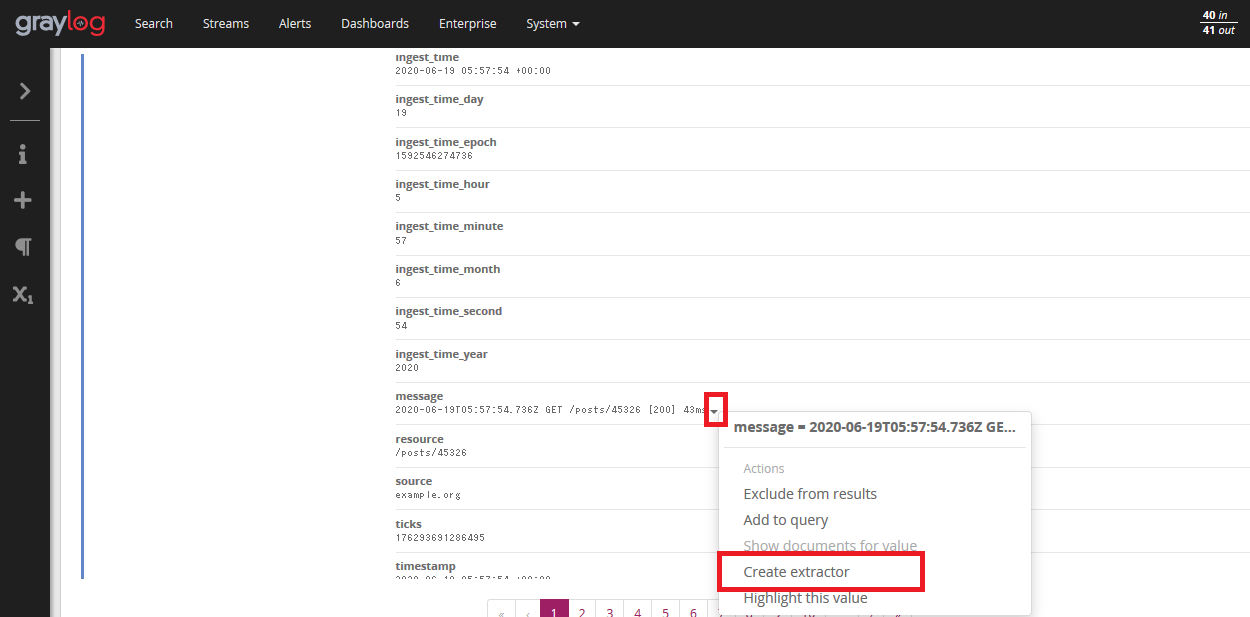
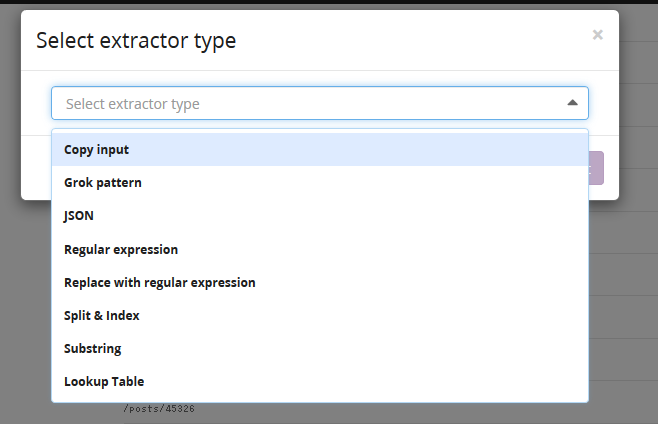
- Graylogは、様々な方法でログを収集することができます。ここでは、Graylogのログ収集と解析の機能について解説します。
- Graylogのシステム構成と拡張性
- Graylogは、ビックデータの解析に利用するOpenSearchを使い高速なログ管理システムです。ここでは、それを実現するためのGraylogのシステム構成とGraylogの拡張性について解説します。
- WindowsイベントログをGraylogで監視・可視化する方法
- ここでは、Graylogにインストールするだけで、すぐにWindowsのイベントログの監視・可視化を設定できる「windows_authentication」について解説します。
- Graylog2.4日本語マニュアル
- Graylogの画面は英語表記です。そのため、時には利用方法が分かりにくく迷うことがあります。こうした問題に対処するために、デージーネットで、独自に作成した日本語マニュアルです。
- Graylog3.3日本語マニュアル
- Graylogバージョン3.3をデージーネットで、独自に作成した日本語マニュアルです。
- Graylog5.1日本語マニュアル
- Graylogのバージョン5.1をデージーネットで、独自に作成した日本語マニュアルです。
- Graylog6.3日本語マニュアル
- Graylogの新しいバージョン6.3をデージーネットで、独自に作成した日本語マニュアルです。