
Apache Solr〜データを高速で全文検索するOSS〜
Apache Solrは、オープンソースの全文検索エンジンです。全文検索とは、ファイル内の全ての文字情報を対象とした検索方法のことです。一回の検索で簡単に検索対象を探すことができて非常に便利ですが、検索に時間がかかる、負荷がかかるといった課題もあります。Apache Solrは、ビッグデータ解析やクラスタ構成の仕組みに対応できるという特徴を持ち、こうした全文検索システムの課題を解決することができます。このページでは、Apache Solrの機能や特徴について紹介します。
- +
目次
Apache Solrとは
Apache Solrとは、Apacheソフトウェア財団のプロジェクトが管理している、オープンソースの全文検索エンジンです。Apacheコミュニティによって開発が進められています。Apache Solr自体はオープンソースソフトウェアですが、これを利用して、いくつかのソフトウェアが製品化されています。また、Apache Solrはプログラミング言語にJavaを使用しており、WindowsやMacでも使用可能です。
全文検索とは
全文検索とは、文書ファイルなどの中に含まれた、すべての文字情報を対象とした検索方法です。フルテキストサーチ(Full Text Search)とも呼ばれます。
例えば、ファイル検索を行う際、ファイル名やフォルダ名だけでなく、ファイルやフォルダの中身のテキストについても検索対象となり、一回の検索で全対象を簡単に探すことが可能です。検索方法としては、最も満遍なく検索できる手法と言われています。ファイルサーバだけでなく、メールサーバやデータベース、Googleなどの検索サイトでインターネット上の様々なドキュメントを検索する際にも、全文検索が利用されています。
全文検索の欠点
ただし、全文検索には以下のような欠点もあります。
- 全文検索に対応したデータベースが必要。一般的なリレーショナルデータベースにも全文検索機能はあるが、スケーラビリティなどの点で課題が多く、データ量が多いと制約がある。
- ビッグデータのような大量のデータがある場合、その中身を逐次的に調べるには膨大な時間がかかる。
- システムが扱う大量のデータにも耐えられる冗長性が必要。
Apache Solrは、これらの欠点を補うことができる全文検索システムです。
各種費用についてのお問い合わせ
コンサルティング費用、設計費用、構築費用、運用費用、保守費用など、各種費用についてのお見積もりは以下のフォームよりお気軽にお問合せ下さい。
![]()
Apache Solrの特徴
Apache Solrには以下のような特徴があります。
ほぼリアルタイムのインデックス作成
全文検索システムで検索を高速に行うためには、主に、形態素解析の機能を用います。形態素解析には、文字列を単語の最小の構成単位に分割する「分かち書き」や、検索対象を単語単位ではなく文字単位に分解する「N-gram方式」などの方法があります。このような形態素解析で索引する文字列を抽出し、インデックスを生成します。Apache Solrでは、このようなインデックス作成やデータ登録を、ほぼリアルタイムで行うことができます。これによって、例えばメールサーバと連携して検索を行う場面では、メールがローカル配送される時に、メールサーバからApache Solrに対してデータを自動的に登録することが可能です。
「構築事例:Apache Solrによるメール全文検索システム」へ
なおデージーネットでは、Apache Solrの特徴を利用したメールアーカイブシステム「AquaVault」を開発しました。「AquaVault」では、メールアドレスごとにアーカイブされた大量のメールの中から、利用者自身が全文検索で必要なメールを見つけ出すことができます。
「ユーザ自身で検索・閲覧できるメールアーカイブシステム〜AquaVault〜」へ
大容量のデータに対応
Apache Solrでは、ビッグデータ解析などで使われるApache Luceneを全文検索エンジンに使っています。Apache Luceneは、高速で、大量のデータにも耐えられるため、Elasticsearchなど数多くの全文検索エンジンで使用されています。そのため、膨大な量のデータを扱うデータベースにも対応し、高速で検索をすることができます。例えば、IoTプラットフォームで利用するコンピュータクラスタ上で、分散解析エンジンとしても活用されています。
冗長化の実現
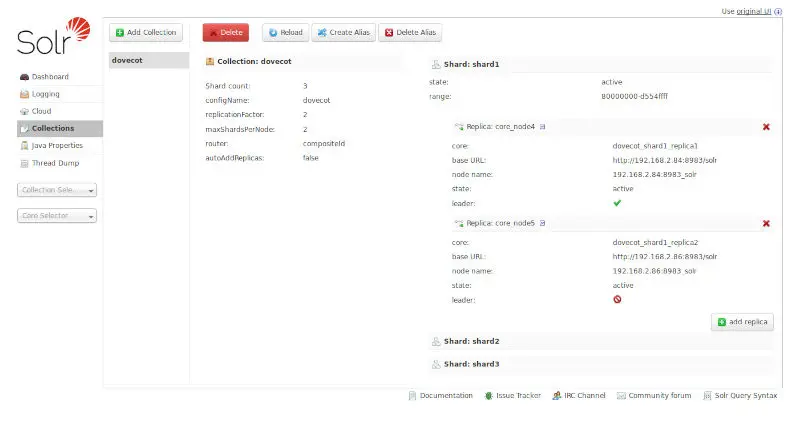
Apache Solrには、Solr Cloudと呼ばれるクラスタ構成の仕組みが用意されており、冗長化したシステム構成をとることができます。このクラスタ構成では、Solrを実行するそれぞれのサーバのことをノードと呼びます。Solr Cloudを使うことで、クエリの負荷分散やフェールオーバーなどを実現することができます。また、設定を集中管理することができます。冗長化の仕組みは以下の通りです。
- Apache Solrは、複数の検索対象を持つことができ、一つ一つの検索対象をコレクションと呼びます。 クライアントは、これらのコレクションに対して登録・検索を行います。
- コレクションが大きくなり、1つのノードで扱うことができない場合には、シャードという単位に分割して管理を行います。
- 各シャードには、 シャードをコピーしたレプリカが配置されます。このレプリカをコアと呼びます。コアは、実際の処理の最小単位です。コアはレプリケーションをサポートしていて、複数のコアをレプリケーションすることで冗長構成を取ることができます。
Apache Solrの機能
Apache Solrには次のような機能があります。
強力な全文検索機能
Apache Solrは、強力な全文検索機能を提供しています。以下のような機能を使用して、検索結果を表示することができます。
- フレーズ検索
検索キーワードを二重引用符(")で囲み、そのキーワードの語順のままで、完全に一致する検索結果を表示することができます。
- ワイルドカード検索
ワイルドカードとは、一部不明な文字の代わりに利用する代替文字のことをいいます。オートフィルタ等であいまい検索をするときに使用します。
- ジョイン操作
対象となる複数のテーブルを結合して検索することができます。
- グルーピング
条件に基づいて、ヒットした検索結果をグループ化して表示することができます。
HTTPを使った登録・検索
Apache Solrへのデータの登録や検索などの操作は、HTTPを使って行います。HTTP上のAPIは、REST-like APIを採用しています。全文検索の対象となるドキュメントの登録および検索結果の出力は、JSON、XML、CSV、バイナリなどの形式に対応しています。
管理者向けGUI
Apache Solrには、Solrコンソールと呼ばれる管理用GUIが付属しており、次のような機能を利用することができます。
|
|
|
プラグインによる機能拡張
Apache Solrは、プラグインによってインデックス作成や検索用の機能などを拡張することができます。プラグインもオープンソースであるため、任意でコードを変更することも可能です。
Apache Solrに関連したソフトウェア
Apache Solrとさまざまなソフトウェアと組み合わせて使うことで、全文検索システムをより便利に活用することができます。以下では、連携できるソフトウェアの例をご紹介します。
Kuromojiを使った日本語対応
Kuromojiとは、Javaで書かれたオープンソースの日本語形態素解析エンジンです。KuromojiはApache Software Foundationに寄付されており、Apache Luceneへの日本語のサポートを提供しています。Kuromojiは、複合語の分割、品詞のタグ付け、見出し化、読みの抽出などの機能を提供します。
Apache Solrで日本語の全文検索を行いたい場合には、このKuromojiを利用するのが一般的です。以前は、形態素解析の機能に制限がありましたが、Kuromojiの採用によって、日本語処理も実用レベルに達しています。
Dovecotなどのメールソフトとの連携
Apache Solrは、POP/IMAPサーバと連携することで、IMAPサーバでの全文検索を実現することができます。
例えば、高機能なIMAPサーバとして有名なDovecotには、「FTS」というプラグインが存在します。これは Dovecotで全文検索を実現するためのプラグインです。さらに別のプラグインとして、「FTS-Solr」が存在します。これはDovecotとApache Solrを全文検索のバックエンドとして利用するためのプラグインです。これらのプラグインを導入することで、Dovecotに全文検索の機能を追加することができます。そのため、非常に速い速度でメールの検索ができるようになります。また「FTS-Solr」には、メールの添付ファイルのフィルタリングをする機能があります。この機能を使うことで、例えばPDFの中身をテキストにして、検索インデックスを作ることができます。つまり、メールの本文の検索で、添付ファイルの中身まで検索が行えるようになります。
Thunderbirdなどのメジャーなメールクライアントや、デージーネットで商用サポートを開始したWEBメールのRoundcubeでも全文検索の機能を利用することができます。
「構築事例:Apache Solrによるメール全文検索システム」へ
また、デージーネットが開発したオープンソースのメールアーカイブシステム「Messasy」でも、Apache Solrを利用しています。MessasyとApache Solrを組み合わせることで、メールアーカイブサーバに保存された過去の大量のメールから、必要なメールを高速で探すことができます。
「メールアーカイブシステムのおすすめOSS〜Messasy〜」へ
Apache ZookeeperによるSolr Cloundの管理
Apache Zookeeperとは、負荷分散システムにおいて、設定情報の管理・命名などの機能を提供するオープンソースソフトウェアです。このZookeeperを利用して、Solr Cloundの設定情報を管理することができます。ZookeeperはApache Solrに同梱されていますが、このバージョンではZookeeper自体の冗長性を確保することはできません。Zookeeperの冗長性を確保するためには、Zookeeperを別途インストールし、最小で3台のサーバを用意する必要があります。各サーバが、互いにデータをレプリケーションして保持することで、冗長化を実現します。
このように、他のソフトウェアを組み合わせることで、様々な用途や目的でApache Solrを使うことができます。
デージーネットの取り組み
デージーネットでは、Apache SolrとIMAPサーバのdovecotを使って、IMAPサーバでの全文検索を実現しています。これにより、メールクライアントからの検索が行われた時には、自動的に全文検索の機能を利用することができます。 例えば、約20000件、700Mバイトのメールデータのメッセージ全体を選択して検索を行った場合、全文検索機能がないと35秒もの時間がかかります。一方、Apache Solrの全文検索機能を使った場合には、一秒以内で検索を終了することができます。今後は、インストール方法やより詳しい機能を調査・検証し、資料を公開していく予定です。
またデージーネットでは、Apache SolrやMessasyなどのOSSを利用したメールアーカイブシステム「AquaVault」を開発しました。アーカイブされたメールを管理者だけでなくユーザ自身が閲覧・検索・ダウンロードすることができるため、誤って削除してしまったメールなどを復元するなど、バックアップ目的として利用することができます。
「ユーザ自身で検索・閲覧できるメールアーカイブシステム〜AquaVault〜」へ
なお、デージーネットでシステム構築サービスを提供したお客様には、導入後支援サービスとして、Open Smart Assistanceを提供しています。Q&A対応、セキュリティ情報提供、障害調査・回避、障害時オンサイト対応・システム再構築などがあります。これは、ソフトウェア単体のサポートではなく、Linuxなどを含むシステム全体に対するサポートです。構築やサポート費用に関する無料見積もりも行っておりますので、お気軽にご相談ください。
「関連情報の一覧」
全文検索の仕組みを導入したメールアーカイブシステム構築事例
今回は、教育関係のお客様へメールアーカイブシステムを構築した事例です。お客様は、以前デージーネットで構築したメールサーバのリプレースを検討しており、メールでの情報漏洩の防止を行いたいというご要望から、特定のユーザに送付されたメールをすべて転送するメールアーカイブシステムを導入しました。
Apache Solrによるメール全文検索システム構築事例
デージーネットが以前に構築したインターネットサービスプロバイダのメールシステムについて、メールの検索が遅く、検索をするとシステムの負荷も高くなる状態を改善できないかと相談を受け対応した事例です。
メールアーカイブシステムのおすすめOSS〜Messasy〜
Messasyは、デージーネットが開発したオープンソースのメールアーカイブソフトウェアです。Postfix, Dovecot, Roundcubeなど、他のオープンソースソフトウェアと組み合わせて使います。受信したメールをアーカイブし、WEBインタフェース上で検索・参照することができます。
ユーザ自身で検索・閲覧できるメールアーカイブシステム〜AquaVault〜
AquaVaultは、デージーネットが開発したメールアーカイブソフトウェアです。Messasyを拡張し、ユーザ自身がアーカイブされたメールを閲覧できるようになりました。監査や不正の抑止力の効果に加え、メールのバックアップとしても役立ちます。
Fess〜全文検索システムのOSS〜
OSSの全文検索システムFessを利用するとどんなことができるのか、どんなところが優れているのかを紹介します。また、Fessについてデージーネットの行っているサービスやサポートについても紹介します。
メールシステムの構築
デージーネットでは、多数のインターネットプロバイダ用のメールシステムをLinuxやOSSを使って構築した実績を背景に、メールシステムをより便利に、より安全に利用する方法を提案します。メールサーバの二重化や、添付ファイルの暗号化、メール承認システムなど、お客様のご要望や環境に合わせたおすすめのメールシステムの構築を実現します。
デモのお申込み
もっと使い方が知りたい方へ
操作方法や操作性をデモにてご確認いただけます。使い方のイメージを把握したい、使えるか判断したい場合にご活用下さい。デモをご希望の方は、下記よりお申込みいただけます。
![]()
